Literate learning
Think stats
When I first approached Clojure my curiosity brough me to look up what people were using to do Data Science in Clojure.
I found a book called Clojure for Data Science, available through my employer's O'Reilly subscription.
I skimmed through it and saw it was introducing stats concepts in a very simple and clear way.
It was using the incanter "framework", which is unfortunately not in development anymore.
The author Henry Garner has also written an interesting essay about his experience with Clojure.
He is also the author of a stats library called kixi.stats.
In the essay he says that what he wrote this library while reading the book "Think stats".
He would re-implement the Python examples in Clojure.
The second edition of the book is available for free and so I went ahead and started reading it. Even though I was familiar with most concepts, implementing them with simple functions and data structures deepened my understanding.
Org code blocks
One of my favourite features of Emcas is org-mode.
It is a markup language (arguably the best), which allows you to mix prose and code blocks.
A code block looks like this:
#+BEGIN_SRC clojure (let [vec [1 2 3]] (reduce + vec)) #+END_SRC
It seems verbose to specify #+BEGIN_SRC and #+END_SRC everytime compared to, for example, markdown.
The process can be quickly automated and it is in fact a built-in feature:
just typing <s and pressing TAB will expand the source block and move the cursor for you so that you can type the language.
Another TAB will bring the cursor inside the block.
Syntax highlighting inside the block is easy to achieve. The big wow moment is when you realize that you can execute code blocks with a backend. Cider kindly provides this backend. When I execute my code block, CIDER will start a REPL.
Not only that, if I use C-C ' to edit the code block, I get a temporary buffer where clojure-mode takes over:
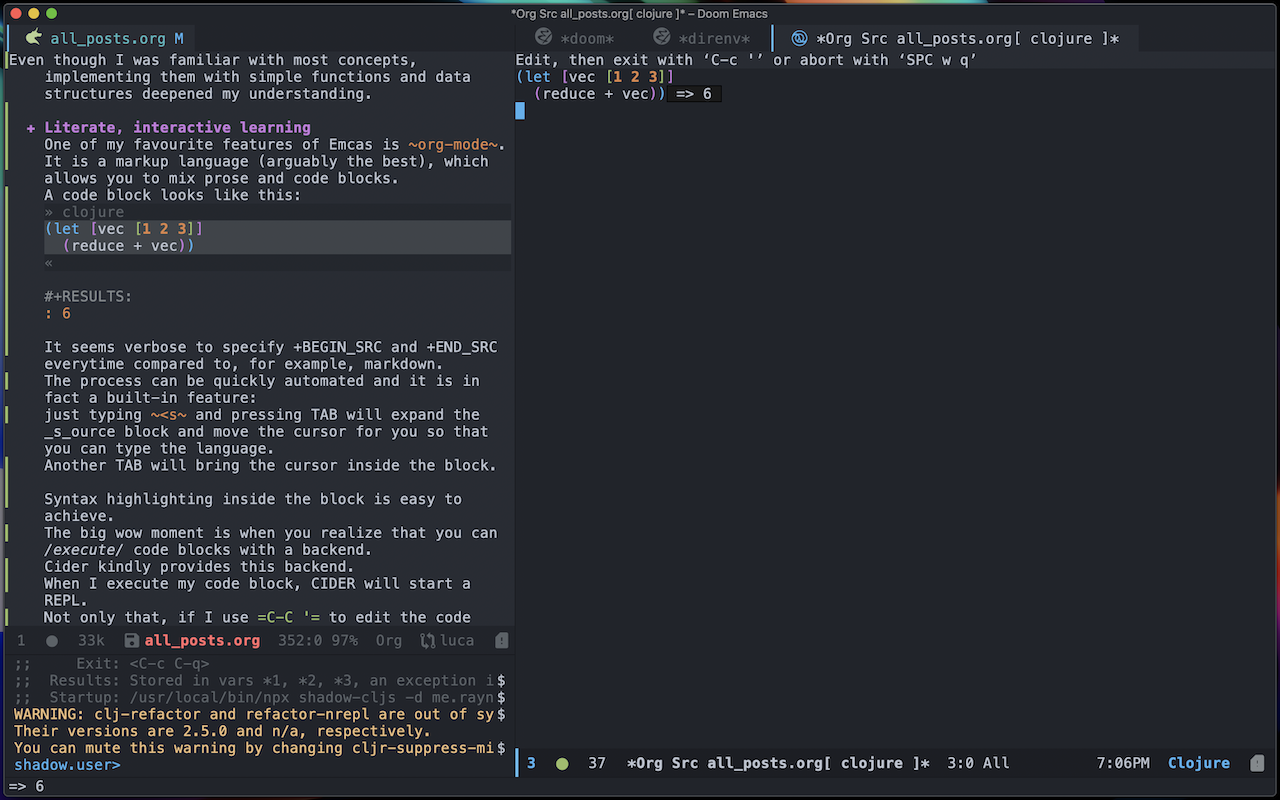
In this screenshot I am editing this blog post in org-mode.
I am editing the source block in the right-window.
When executing it, a shadow-cljs nREPL server was started and org-mode seamlessly connected to the session.
I can evaluate the let form with CIDER and print the result in the buffer.
All of the amazing CIDER features are available (refactor, debug).
Wait for the second wow moment.. you can execute different languages in the same document. Org mode provides the means for sharing simple data structures between languages. What is not supplied can be achieved easily by serializing intermediate results with one language and re-loading it in another language. Data analysis in Python, visualization in R, no context switching.
You will need to give up Pycharm and Rstudio magics, though.
Some people might consider this is a good thing.
You need to understand what Pycharm handles behind the scenes and build it (better: compose it) yourself.
In 5 years maybe there will be another IDE leading the market.
I am pretty sure org-mode will still be there, along with the low-level concepts you learned in the effort.
An org-mode file is structured in sections, or headings.
Each of these headings can have subheadings.
They can be collapsed and expanded easily by Emacs.
This is very consistent with the structure of a book.
Notes are naturally organized in sections and subsections of the book. The python code snippets of the book can be copied, pasted and executed. Below I can open a clojure code snippet and rewrite it.
Org inline plots
Another fantastic feature of org-mode's inline images.
In fact we can embed the result of a plot directly in the document.
Nowadays, with Jupyter Notebooks, this is expected and almost required.
Without much effort, I managed to embed .png files produced by vega-lite.
For that I am using a thin clojure wrapper over vg-cli.
This is an example of a source block which outputs graphics:
(defn plot-spec [spec] (vg/vg-cli {:spec spec :format :png :output-filename "data/plots/tmp.png"})) (let [ds (ds/->dataset "data/thinkstats/nsfg.csv") spec {:data {:values (-> (ds/filter #(== 1 (get % "outcome")) ds) (ds/select-columns ["prglngth"]) (ds/mapseq-reader))} :mark "bar" :encoding {:x {:field "prglngth" :type "quantitative"} :y {:aggregate "count" :type "quantitative"}}}] (plot-spec spec))
As described in my previous blog post, the specification is expressed in clojure and passed to the vg-cli, which writes the .png to a path.
Note that the code block has certain header args:
#+BEGIN_SRC clojure :results graphics file link :file ../../data/plots/tmp.png ...
#+end_src They set the result to be a link to the path where the plot will be saved.
Clojer to metal
Reading this book with this setup is a lot of fun. I usually have the .pdf open on the right and Emacs on the left. I can focus on one topic at a time, code in both languages, quickly see some plots.
The python code often uses pandas, numpy, matplotlib.
I am replacing them with tech.ml.dataset + tablecloth, fastmath and vega-lite respectively.
The dataset abstraction in the Clojure world is better than the pandas one.
I can express myself with maps and reduce on datasets or columns.
After a groupby, I can operate on each grouped dataset.
Which is nothing more than a sequence of maps.
No series, no index, no arcane syntax.
I could implement most functions like percentile or covariance on my own.
When things get more complicated, I am relying on fastmath, which mostyly wraps org.apache.commons.math3.
So far I used it for sampling from distributions and computing the kernel density estimate.
Speaking of visualizations, vega-lite has really been a pleasure to use.
Plots are supposed to be simple.
You either have a bar plot, a line plot or a scatter plot.
What is on the x axis and what is on the y axis?
We usually have a sequence of maps containing xs, we can map functions over them to obtain ys, plot them.
vega-lite makes it also extremely easy to compose visualizations: auto-layer them, concatenate them vertically, horizontally.
This means that I can derive my building blocks as functions and very quickly compose them.
Again, not a slave of matplotlib APIs: subplots, xticks formatters and so on.
Visualizations as data.
Here is a snippet demonstrating tablecloth and vega-lite layers:
(defn weight-vs-height-mapseq [ds rank] (-> (ds/select-columns ds ["htm3" "wtkg2"]) (dss/drop-missing ["htm3"]) (dss/select-rows (fn [row] (and (> (row "htm3") 135) (< (row "htm3") 200)))) (dss/group-by (fn [row] (dfn/round (dfn// (row "htm3") 5)))) (dss/aggregate {:mean-height #(dfn/mean (% "htm3")) :weight-percentile #(percentile ((dss/drop-missing % "wtkg2") "wtkg2") rank)} ) (ds/mapseq-reader))) (let [specs (for [[rank color] [[25 "blue"] [50 "green"] [75 "red"]]] (line-spec (weight-vs-height-mapseq brfss rank) :x-field :mean-height :y-field :weight-percentile :mark-color color))] (plot-spec {:layer (into [] specs)}))
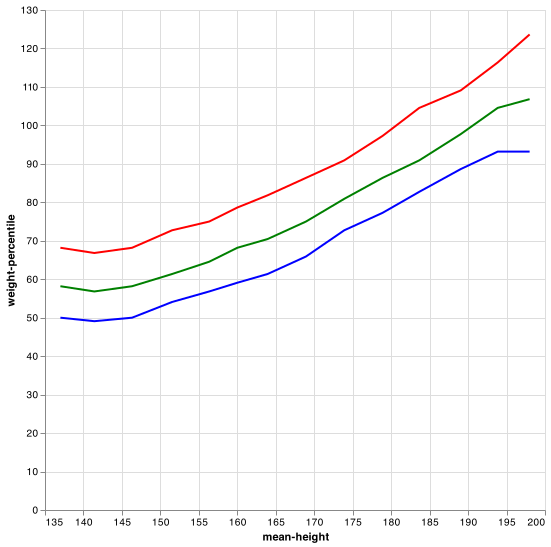
Apart from these super cool libraries, I am gaining confidence with the language. I am solving problems faster, writing more idiomatic code (I like to refactor days-old code, extracting pure functions), getting comfortable with the tooling. I like the idea that these pure functions are forever added to my toolbox, ready to be applied to other problems and domains.
Conclusion
This post has briefly touched some topics and technologies that are really interesting to me such as data science, literate programming and clojure. I barely scratched the topic of literature programming but I was glad to experiment with one of its use cases. I will write another post in the future which showcases some other cool features such as weaving and tangling. I hope that somebody can learn from the approach that I shared and maybe can suggest improvements to this workflow!