Discovering org-roam
The problem of processing information efficiently
I read a lot of interesting stuff every day. New software I want to try, articles I want to read, material that I want to save for future reference.
I am constantly processing information and trying to internalize as much as possible. I think it is a very critical problem in this age and of course smart software and techniques have been invented to tackle it.
I have always heard very good things about Roam Research and its emacs package org-roam .
Recently, org-roam v2 has been released and I finally had some time to play with it to see what the hype was about.
After few hours with it I already know I discovered an invaluable tool that will accompany me for life.
In this blog post I will try to explain why that is and how I use it.
Roam and Zettelstalken
The Roam software centers around the Zettelkasten method. To be honest, I have read the definition multiple times without really understanding the magic behind it. Anyway, here it is:
A zettelkasten consists of many individual notes with ideas and other short pieces of information that are taken down as they occur or are acquired. The notes are numbered hierarchically, so that new notes may be inserted at the appropriate place, and contain metadata to allow the note-taker to associate notes with each other. For example, notes may contain tags that describe key aspects of the note, and they may reference other notes.
…
The method not only allows a researcher to store and retrieve information related to their research, but also intends to enhance creativity. Cross-referencing notes through tags allows the researcher to perceive connections and relationships between individual items of information that may not be apparent in isolation.
Paraphrasing with my own words, the method consists of 2 actions:
- Capturing short notes with good metadata, which results in connected notes
- Regularly inspecting notes to find not obvious connections/topics/clusters of information
I think the best way to understand what these words mean is by showing a couple of very good example implementations of this method:
Websites like these are sometimes affectionately called "digital gardens". Often well curated, they are a public exhibition of a person's thoughts and interests. It is an amazing invention.
Andy has very interesting notes about effective note taking and has a beatiful website to navigate and consult his network of thoughts. Among them, one note in particulare stroke me: Collecting material feels more useful than it actually is . This is just one of the many mind-blowing notes Andy has curated over the years.
I am personally guilty of accumulating interesting browser tabs, until I reach hundreds. Then one day I set aside 2 hours to "capture" them in a single file with tags. The tabs are gone, archived in a text file… which I never open again. The knowledge is lost, stale.
He argues that in order to internalize something we need to re-elaborate it, curate it. We should also be able to let go some of these resources because they are not so precious. Let's add action number 3 to the Zettelkasten method: improve and enrich your existing notes.
Hugo's website has an amazing visualization of his connected notes. This is a really cool way to perform action number 2 I have outlined above.
Personal wikis should not have a hierarchy
I hope I managed to give a glimpse of what can be achieved with this methodology. I talked about my ineffective method of "capturing" my browser tabs. The second element of my method is my "org" folder, which is what I consider my personal wiki.
In this folder I have subfolders such as "personal", "work". Maybe under work I will have subfolders such as "forecasting" or "spark". This gives us the opportunity to discuss another important argument of the Zettelkasten method: notes should not have an hierarchy but structure should emerge spontaneously. Andy has a beautifully written note about this concept.
When I want to add something to my wiki, I don't want to worry about where to place the information (is it personal? is it work? is it machine learning or reinforcement learning?). I capture the blog post, notes about a book, youtube video, podcast and I add metadata. Then, smart software automates the process of creating a network of notes and visualizing it.
I just finished converting my structured wiki into an unstructured one and it works much better.
Let's make an example.
I had an org file called workflow.org, where I had collected information about different software I use.
One heading for emacs, one heading for python, one heading for docker…
One subheading for emacs is org-mode, with all the keybindings and useful functions.
Each heading (and potentially subheading) has been turned into a node (take a look at Hugo's Notes graph).
It makes sense to have an emacs node, to which other nodes can refer to.
For example org-mode is a node referring to it.
The package org-roam I am about to describe is another node linking to both emacs and org.
Hierarchy is teared apart and structure emerges spontaneously.
Whenever I want to add a new note about org, I will just add a new node and refer to the org node, I don't need to care about which folder or file to write it in.
I will also connect it with more concepts, maybe with evil-mode.
Retrieving, inspecting and adding information is much smoother, it really is a knowledge library with a very smart librarian.
org-roam
I am extremly grateful to the author of org-roam for creating an interface to Roam that is accessible from emacs.
Here you can find his website (and blog and digital garden).
How does it work in practice?
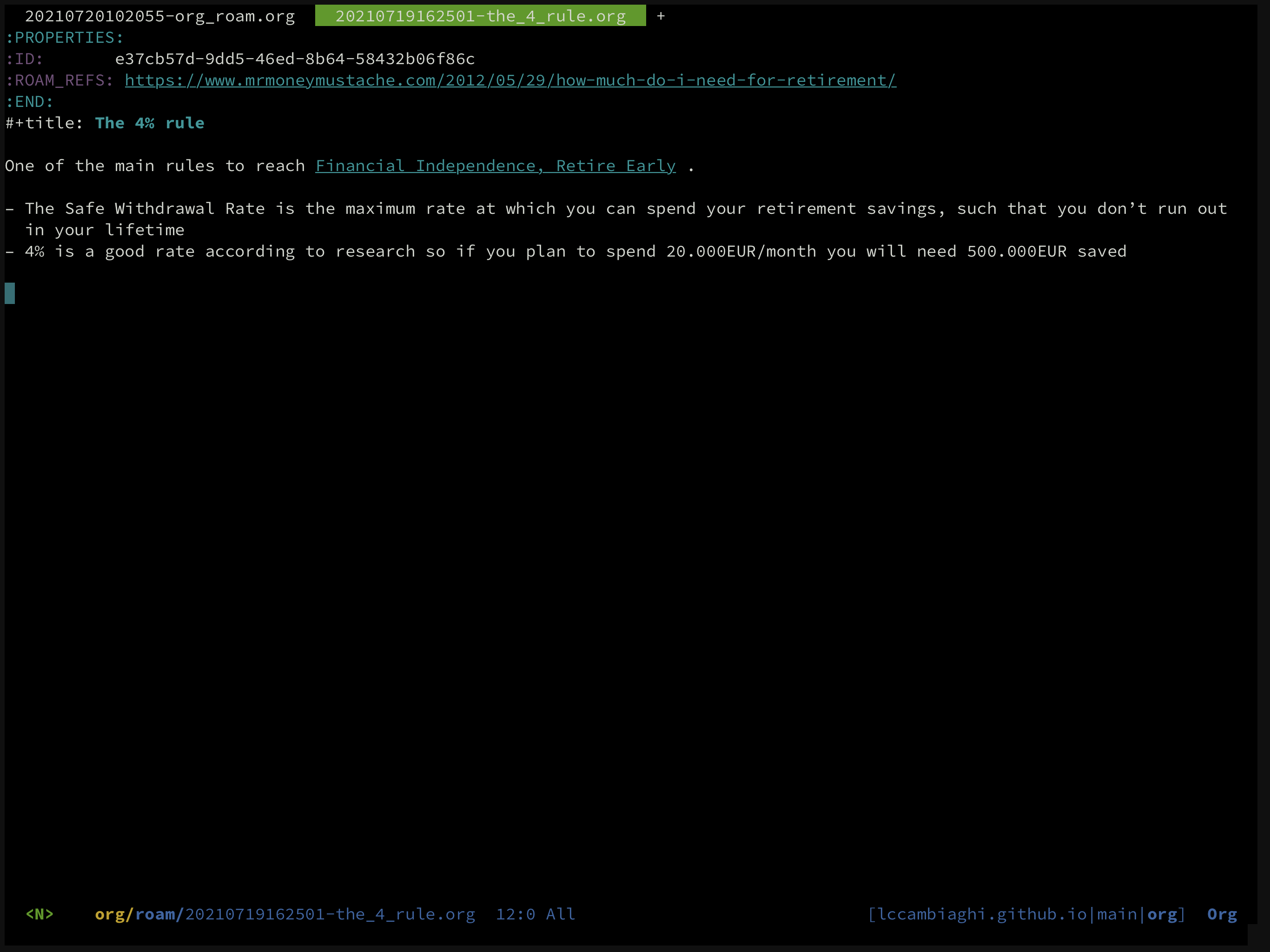
Let's say I am reading about FIRE and I want to capture this article about the 4% rule.
First, I will call org-roam-node-find (SPC n f) and type the title "4% rule".
Since the node does not exist, a new one will be created.
Then, I will add a reference with org-roam-add-ref (SPC n r) and add the URL of the article.
Finally, I will write my own interpretation of the article, in which I will link to other nodes in my network with org-roam-node-insert (SPC n i), among which the "Financial Independence, Retire Early" node.
This is the resulting note/node:
I can now org-roam-node-find and go to the "Financial Independence, Retire Early" node.
I then org-roam-alias-add to add the "FIRE" alias to the node so that it is easier to reference it.
Now nodes can reference to it also by using +filetags: FIRE (otherwise whitespace becomes a problem).
Finally, we can use org-roam-buffer-toggle (SPC n b) to reveal the org-roam buffer which shows us the backlinks, i.e. the nodes that reference the "FIRE" node.
In the screenshot below we can see 3 backlinks, which we can navigate to in an instant.
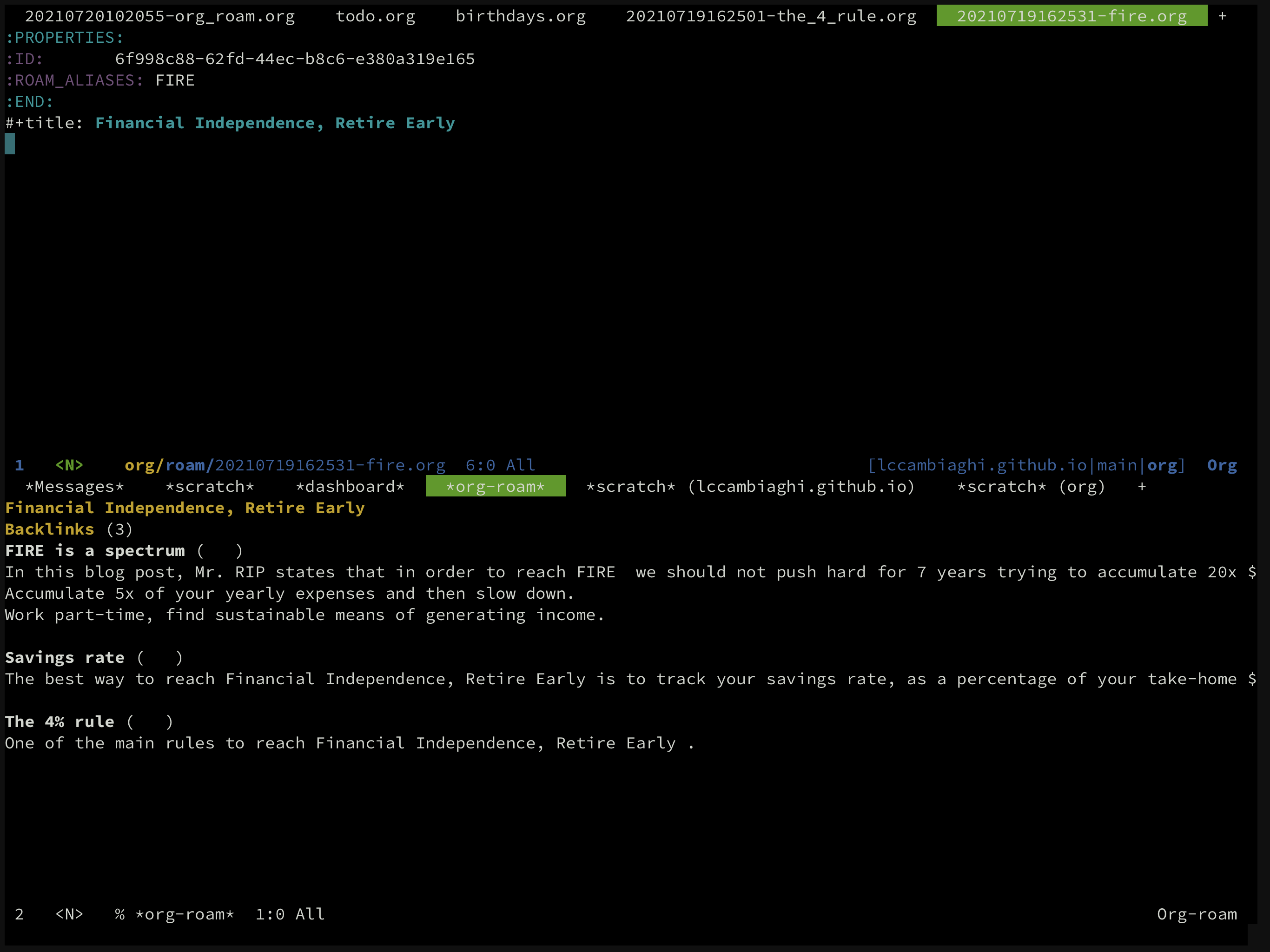
It is an amazing system, after few captures I felt right at home with a new set of standards. The community is developing a new tool to visualize the connected notes, I am looking forward to it.
Conclusion
In conclusion, I am very glad I spent some time trying to understand Roam and its ecosystem.
It's only been a day so I am sure that with the time I will improve my workflow and discover mistakes and new things.
It is however impressive to see how much org-roam empowers you from day one.
I hope you enjoyed this blog post and please let me know in the comments if something is not clear or plain wrong.
For the attentive reader which read my previous blog post, yes, I am using org-roam from my main computer, i.e. my iPad Pro.
It works like magic!
The only "issue" is that I can't use the built-in org-roam-graph because I am missing the graphviz dependency (a kind Procursus developer is already trying to help).